序言
在各种类型的网站上,你都可以见到一个很常见的组件——搜索框。
用户搜索的目的自然是想找到自己期望的数据,那么,作为程序员,我们会如何实现搜索功能呢?
对于少量的数据,我们会使用 MySQL 的LIKE模糊搜索来满足该需求,但是,现在很多业务场景下的数据都是海量的,这时候再继续使用 MySQL 的话,就不太合适了。
为什么呢?
因为呀, MySQL 的LIKE全文检索会对数据库中所有数据进行逐行匹配输入的关键字,因此效率比较低。
为了提高检索的效率,目前绝大多数公司都在使用 ElasticSearch,那么下面跟随本篇文章来了解下 ElasticSearch 是什么东东吧!
简介
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
功能特性
- 开源免费:基于 Apache License 2.0 开源协议,并且完全免费
- 基于 Java 语言:Elasticsearch 基于 Java 语言开发,运行在 JVM 环境中
- 基于 Lucene 框架:基于开源的 Apache Lucene 框架开发
- 分布式:不依赖与 Zookeeper,自带分布式解决方案
- 大数据:支持海量数据的全文检索
- 高性能:支持 PB 级数据秒内响应!对于 ES 来说,上亿级别数据只不过是起点!性能几乎没有上限,足以满足各种对性能要求极高的场景
- 可伸缩:弹性搜索,可根据不同规模服务对性能需要的不同而动态扩展或收缩性能
- 易扩展:支持非常方便的横向扩展集群
- 开箱即用:下载解压后零配置启动服务即可立即使用,门槛极低
- 跨编程语言:支持 Java、Golang、Python、C#、PHP 等多种语言
为什么使用 ElasticSearch?
众所周知!几乎没有一款软件是没有搜索功能的,而毫不客气的说,只要是用到搜索的场景,ES 几乎都可以说是最好的选择,ES 适用于所有数据类型,无论是数字、文本,还是地理位置,既支持结构化数据,又支持非结构化数据。
除此以外,全文本搜索只是全球众多公司利用 Elasticsearch 解决各种挑战的冰山一角,ES 还支持在以下场景使用:
- 日志监测:快速且可扩展的日志管理,绝不会让您失望
- 基础架构监测:对您的系统指标进行监测和可视化
- APM:深入洞察应用程序的性能
- 合成监测:监测可用性问题并进行应对
- 企业搜索:提升任何用例的搜索和发现体验
- Maps:实时探索位置数据
- SIEM:交互式调查和自动威胁检测
- 终端安全:预防、检测、猎捕并应对威胁
基本概念
倒排索引
ElasticSearch 之所以比 MySQL 检索快,最重要的原因就是它特有的数据结构——倒排索引。
ElasticSearch 为了便于数据的搜索,使用了一种特有的数据结构——倒排索引来存储数据,这能在检索数据的时候快速定位。
平常我们都是先找到一个文档,再在其中搜寻我们想要的关键字。
但在 ElasticSearch 中不同的是:
- 先搜索
term - 根据
term找到对应文档id - 最后根据文档
id找到文档并展示其信息
因为索引的目的是利于搜索,毕竟最终要实现的目标是——只搜索被索引的term就可以找到用户想要的文档。
那么,搜索时就会去前面创建好的索引表中查找数据啦!
因此,索引由以下 3 部分组成:
term- 构造完的文档
term与文档间的映射(对应关系)
索引库的数据结构被叫做倒排索引结构,亦叫反向索引结构。
一个倒排索引包括term表和与之对应的文档表两部分,term表即词汇表(单词表),它的规模较小,而文档表集合较大。
下面为倒排索引的图示:
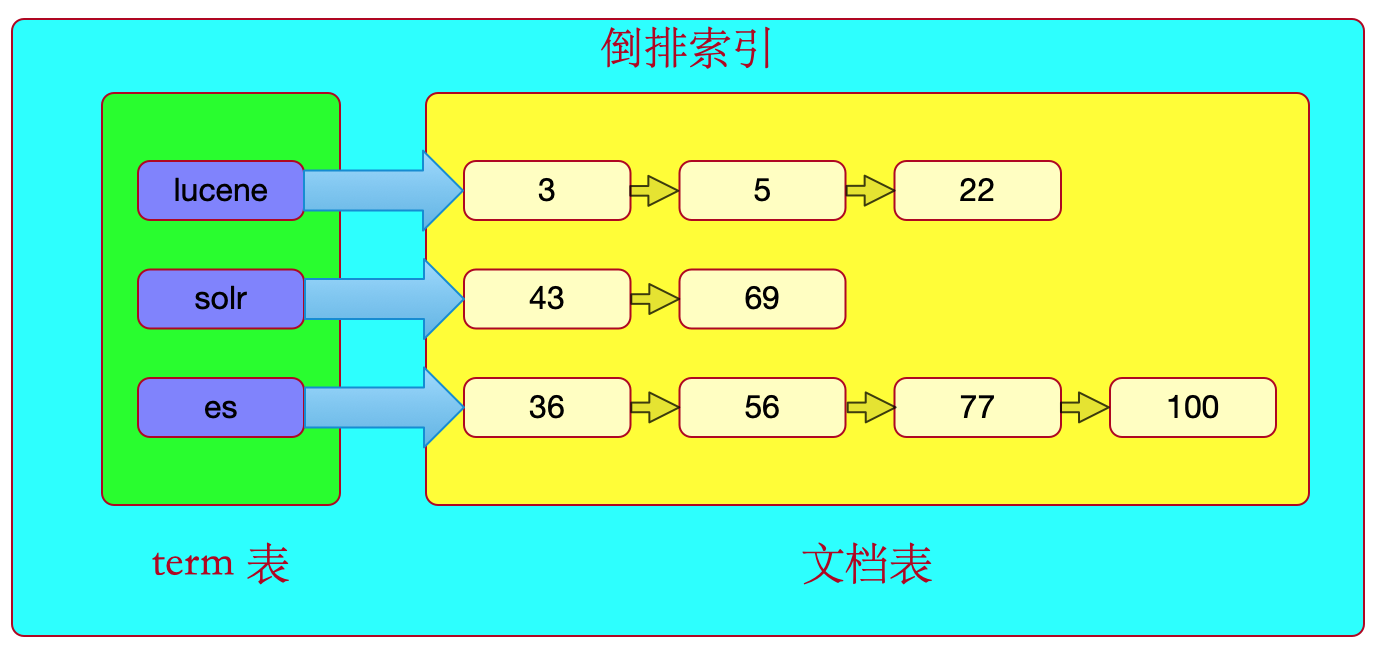
比如,通过lucene这个term,可以找到文档 ID 为3、5、22的这些文档。
注意哦:默认情况下,对 ElasticSearch 的字段而言,无论 ES 有没有分词,都会对字段建立倒排索引。
不仅如此,ElasticSearch 在倒排索引的基础上,衍生了一种Doc Values的数据结构,这对聚合非常有用。
倒排索引建立过程——分析(Analyzes)
分析是将输入的内容重新打散整理并存储的过程。
分析的过程
分析包含下面的过程:
- 首先,将一块文本分成适合于倒排索引的独立的单词
- 之后,将这些单词统一化为标准格式以提高它们的“可搜索性”
上述过程由分词器(分析器)的 3 个相关功能来执行,这包括:
Character filters:字符过滤器。首先,字符串按顺序通过每个字符过滤器,它们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉 HTML 或者将 & 转化成 andTokenizer:Token 分词器。其次,字符串被Tokenizer分为单个的单词。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成单词Token filters:Token 过滤器。最后,单词按顺序通过每个 Token 过滤器 。这个过程可能会改变单词(比如将 Quick 小写),删除词条(比如删除像 a, and, the 等无用词),或者增加词条(比如 jump 和 leap 这种同义词)
Elasticsearch 提供了开箱即用的字符过滤器、Token 分词器和 Token 过滤器, 它们组合起来形成自定义的分析器以用于不同的目的。
分词器的种类
分词器的种类很多,下表列举了常见的几个:
| 种类 | 说明 | 应用场景 |
|---|---|---|
| space | 在空格的地方划分文本 | |
| simple | 在任何不是字母的地方分隔文本,将单词小写 | |
| standard | 根据 Unicode 联盟定义的单词边界划分文本,删除绝大部分标点,最后将单词小写 | 英文分词 |
| ik-analyzer | 对中文“我家住在黄土高坡”分词为“我”、“家”、“住”、“黄土”、“高坡”、“黄土高坡” | 中文分词 |
注:ik-analyzer属于语言分词器的一种。
什么时候使用分词器?
一般在获取文档对象之后,对文档对象分析后建立倒排索引的过程中,会用到相关分词器。
分析过程示例
获取到文档(文章)对象之后,对里面的数据:1
2<p>Lucene is a Java full-text search engine. </p>
<p>Lucene is not a complete application, but rather a code library and API that can easily be used to add search capabilities to applications.</p>
在 Elasticsearch(Lucene) 中,会经历以下步骤:
① 首先通过字符过滤器去除HTML标签:1
2Lucene is a Java full-text search engine.
Lucene is not a complete application, but rather a code library and API that can easily be used to add search capabilities to applications.
② 其次,对原始数据进行提取:根据空格进行字符串拆分,得到一个单词列表:1
2
3
4
5
6Lucene
is
a
Java
full-text
...部分省略...
③ 把得到的单词列表转换成小写:1
2
3
4
5
6lucene
is
a
java
full-text
...部分省略...
④ 去除标点符号:1
2
3
4
5
6
7lucene
is
a
java
full
text
...部分省略...
⑤ 去除停用词(无太大意义的词:如is、a、and等):1
2
3
4
5lucene
java
full
text
...部分省略...
⑥ 将其分词后得到的单词(token)为:lucene、java、full、text、engine等。
⑦ 最后,每个单词都将被封装到一个Term对象中。
Term是什么呢?
Term是搜索的最小单元Term由两个元素组成:单词(token)本身和单词所在的字段(Field)- 文档的一个可索引的字段对应一个倒排索引
Term不仅可以表示字符串词语,还可以代表日期型值、邮箱地址、URL
简单来讲,Term就是一个包含指定Field和目标词语的一个对象。比如:1
Term term = new Term("content", "java");
因此,上面的Term对象就是表示需要查询在content这个字段(Field)中出现过java这个token(单词)的文档。
⑧ 对所有文档分词得出的Term进行汇集并创建索引后,会将其保存到索引库中。
注:token会记录分词后每个词语的位置,偏移等信息,可以理解为更细粒度的term
数据类型
基础(简单)数据类型
Elasticsearch 支持以下简单的字段类型:
| 类型 | 说明 |
|---|---|
text、keyword |
字符串 |
byte、short、integer、long |
整数 |
float、half_fload、scaled_float、double |
浮点数 |
boolean |
布尔值 |
date |
日期 |
binary |
二进制 |
integer_range_、float_range_、date_range_(部分) |
区间 |
其中,对text和keyword来说:
text:可分词,只允许检索,不允许排序和聚合keyword:不可分词,却即可检索(完全匹配)也可排序和聚合
这些不同的字段类型索引方式是不同的,因此导致查询结果的不同。
我们肯定期望每一种数据类型应该以不同的方式进行索引,而这点也是现实:在 Elasticsearch 中,它们是被区别对待的。
为什么要区别对待呢?
最大的区别在于精确值(Exact values)及全文文本(Full text)之间。
上述两者的区别真的非常重要,因为这是区分搜索引擎和其他数据库的根本。
精确值(Exact values)VS 全文文本(Full text)
在 Elasticsearch 中,数据可以大致分为两种类型:
- 精确值(除
text外所有类型) - 全文文本(
text)
精确值
精确值,正如它的名字一样,是确定的。
比如一个用户 ID或一个日期,字符串也可以表示精确值,例如用户名或邮箱地址。
但需要注意的是,对精确值而言:
- 精确值(用户名)
"Lovike"和"lovike"就并不相同 - 精确值(日期)
2020和2020-09-15也不相同
换而言之,精确值必须完全匹配。
全文文本
全文文本,从另一个角度来说是文本化的数据(常常以人类的语言书写),比如一篇文章、一封邮件。
全文文本常常被称为非结构化数据 ,但其是一种用词不当的称谓,毕竟实际上自然语言是高度结构化的。
问题是自然语言的语法规则是如此的复杂,计算机难以正确解析。
比如下面句子:1
May is fun but June bores me.
它到底指的月份还是人呢?
对比
精确值更易查询,因为结果是二进制的——要么匹配,要么不匹配。
比如下面的查询很容易以 SQL 来表达:
1 | WHERE name = "Lovike" |
但是,对于全文数据的查询来说,就有些微妙了。
我们不会去了解一篇文章是否匹配查询要求,但是,我们想知道查询条件与这篇文档匹配程度如何。
换句话说,对于查询条件,这篇文档的相关性有多高?
我们的目的是什么呢?
我们仅仅是想要通过查询条件去获得出多篇文章罢了。
然而,我们一般不会去确切的完全匹配整个全文文本,而只想在全文中查询出包含查询文本的部分。
不仅如此,我们还期望搜索引擎能理解我们的意图,即能够联想,比如:
- 一个针对 “UK” 的查询将返回涉及 “United Kingdom” 的文档
- 一个针对 “jump” 的查询同时能够匹配 “jumped” , “jumps” , “jumping” 甚至 “leap”(同义词)
- “johnny walker” 也能匹配 “Johnnie Walker” , “johnnie depp” 及 “Johnny Depp”
- fox news hunting 应该返回福克斯新闻( Foxs News )中关于狩猎的故事,同时, fox hunting news 应该返回关于猎狐的故事。
复杂数据类型
除了简单数据类型, ES 中还有复杂数据类型,包括:
- 数组
- 对象
- null 值
数组
若我们希望 tag 字段包含多个标签,可以以数组的形式索引标签:1
2
3{
"tag": [ "MySQL", "Redis" ]
}
注意哦:数组中所有的值必须是相同数据类型的
null 值
当然,数组可以为空。
事实上,在 Lucene 中是不能存储 null 值的,所以我们认为存在 null 值的字段为空字段。
下面三种字段被认为是空的,它们将不会被索引:1
2
3"null_value": null,
"empty_array": [],
"array_with_null_value": [ null ]
对象
ES 中,JSON 原生数据类就是对象。
数据模型
Elasticsearch 是基于 Lucene 的全文检索库,本质也是存储数据,许多概念与传统关系型数据库(如 MySQL )类似。
下表来为传统关系型数据库与 Elasticsearch 间的对比:
| Relational DB | Elasticsearch |
|---|---|
| 数据库(Databases) | 索引集(Indeices) |
| 数据表(Table) | 类型(Type) |
| 行(Row) | 文档(Document) |
| 列(Column) | 字段(Field) |
| 模式(Schema) | 映射(Mapping) |
| 查询(SQL) | 查询(DSL) |
| 分库分表 | 分片(Shard) |
| 备份 | 副本(Replica) |
从上表可知,Elasticsearch 中:
- 可以包含多个索引(indices –> 数据库)
- 每一个索引可以包含多个类型(types –> 表)
- 每一个类型又可包含多个文档(documents –> 行)
- 每个文档包含多个字段(Fields –> 列)
- 索引结构定义则使用 Mapping
- 查询使用 DSL
- 分片与分库分表有点类似,但区别还是很大的
Elasticsearch 中这些概念,下面将详细介绍。
注意:在不同版本的 ES 中,上述类比可能不准确,出于性能方面的考量,ES 7 之后不推荐使用 Type,ES 8 之后则禁止使用 Type
Index
索引(index)类似于关系型数据库里的“数据库”(database),即存储和索引关联数据的地方。
需要注意的是:索引(index)这个词在 Elasticsearch 中有着不同的含义:
- 索引(名词):一个索引(index)就像是传统关系数据库中的数据库,它是相关文档存储的地方, 其复数为 indices 或 indexes
- 索引(动词):「索引一个文档」表示把一个文档存储到索引(名词)里,以便它可以被检索或者查询。这很像 SQL 中的 INSERT 关键字,差别是,若文档已经存在,新文档将覆盖旧文档
- 倒排索引:传统数据库会为特定列增加一个索引,如用 B-Tree 索引来加速检索。Elasticsearch 或 Lucene 则使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的
默认情况下,文档中的所有字段都会被索引(拥有一个倒排索引),只有这样他们才是可被搜索的。
ES 索引创建成功之后,以下属性将不可修改
- 索引名称
- 主分片数量
- 字段类型
- 字段分词器(默认
standard)
Type
在应用中,我们使用对象来表示一些“事物”,例如:
- 一个用户
- 一篇博客
- 一个评论
- ……
每个对象都属于一个类,这个类定义了属性或与对象关联的数据。 比如 User 类的对象可能包含姓名、性别、年龄和 Email 地址。
在关系型数据库中,我们经常将相同类的对象存储在一个表里,因为它们有着相同的结构。
同理,在 Elasticsearch 中,使用相同类型(type)的文档来表示相同的“事物”,因为它们的数据结构也是相同的。
每个类型(type)都有自己的映射(mapping)或者结构定义,就像传统数据库表中的列一样。所有类型下的文档被存储在同一个索引下,但是类型的映射(mapping)会告诉Elasticsearch 不同的文档如何被索引。
版本差异
注意哦:在 ES 7 之后不推荐使用 Type,而 ES 8 之后则禁止使用 Type.
为什么要删除 Type 的概念
- 逻辑不合理:把 Type 理解为关系型数据库中的 Table 是错误的类比,官方后来也意识到了这是个错误。在 SQL 数据库中,表是相互独立的,一个表中的列与另一个表中的同名列无关。对于映射类型中的字段,情况并非如此。
- 数据结构混乱:在 ES 中,不同映射类型中具有相同名称的字段在内部由相同的 Lucene字段支持。比如说,在 ES 的同一个索引上分别创建 user type 和 order type,在两 type 中均创建 user_name 字段,按关系型数据库的理解,这两个 user_name 应该存储在不同位置,但实际上 ES 的两个类型中的 user_name 字段会存储在完全相同的 user_name 字段中,并且两个 user_name 字段在两种类型中必须具有相同的映射(这显然不合理)
- 影响性能:最重要的是,在同一索引中存储具有很少或没有共同字段的不同实体,会导致数据稀疏,并干扰 Lucene 有效压缩文档的能力
基于以上原因,官方决定从 Elasticsearch中 删除 Type 的概念。
官方希望 ES 使用者为每个文档类型设置一个索引,而不是把 user 和order 存储在单个索引中。此种做法有以下好处:
- 索引彼此完全独立, 因此索引之间不会存在字段类型冲突。
- 避免了稀疏字段,数据更密集,有利于提高 Lucene 中对索引的压缩效率
- 在全文搜索中用于评分的术语统计信息更准确, 因为同一索引中的所有文档都表示单个实体
- 索引粒度更小, 方便动态优化每个索引的性能,比如可以分别为两个索引单独设置不同的分片数量
Document
什么是文档?
程序中大多的实体或对象能够被序列化为包含键值对的 JSON 对象:
- 键(key)是字段(field)或属性(property)的名字
- 值 (value)可以是字符串、数字、布尔类型、另一个对象、值数组或者其他特殊类型。
通常,我们可以认为对象和文档是等价的。
不过,它们还是有所差别:对象是一个 JSON 结构体——类似于哈希、hashmap、字典或者关联数组;而对象中还可能包含其他对象。
在 Elasticsearch 中,文档这个术语有着特殊含义,它特指最顶层结构或者根对象序列化成的 JSON 数据(以唯一 ID 标识并存储于 Elasticsearch 中)。
在 Elasticsearch 中,文档归属于一种类型(type),类型类似于关系型数据库中数据表的概念,而这些类型则存在于索引(index)中。
文档元数据
其实,一个文档中不只有数据,它还包含了元数据——即文档的信息。
其中,三个必须的元数据节点是:
| 节点 | 说明 |
|---|---|
| index | 文档存储的地方 |
| type | 文档代表的对象的类 |
| id | 文档的唯一标识 |
id
id 仅仅是一个字符串,它与 index 和 type 组合时,就可以在 Elasticsearch 中唯一标识一个文档。
注意点:当创建一个文档时,可以自定义 id ,也可让 Elasticsearch 自动生成。
Mapping
注意:前置条件需阅读 数据类型 -> 基本数据类型
Elasticsearch 中的映射(Mapping)类似于关系型数据库的模式(Scheme),即建表时定义字段的相关属性。
因此,映射定义了字段类型对应的数据类型及字段被 Elasticsearch 处理的方式(比如说字段是否被 store 或 index)。创建一个映射定义,其中包含一个与文档相关的字段列表。映射定义还包括元数据字段,比如_source字段,它可以自定义如何处理一个文档的相关元数据。
在 ES 中,映射可分为两类:
- 动态映射
- 静态映射(显式映射)
动态映射
当我们索引(创建)一个包含新字段(之前未创建)的文档,Elasticsearch 将使用动态映射来猜测字段类型,猜测字段类型的类型源自于 JSON 输入的基本数据类型,因此会使用以下规则:
| JSON 数据的类型 | 动态映射猜测的字段类型 |
|---|---|
布尔值,如true或false |
boolean |
整数,如123 |
long |
浮点数,如99.80 |
double |
日期字符串,如"2020-5-20" |
date |
字符串,如"hello world" |
string |
比如,我们在 ES 中创建一条数据:1
2
3
4
5
6POST /user/_doc/1
{
"name": "lovike",
"age": 18,
"desc": "正在上班"
}
动态映射将根据输入的 JSON 数据的类型来猜测字段类型。
静态映射(显式映射)
既然有动态映射,那么也就有静态映射(显式映射)。
静态映射允许我们自定义映射的数据类型。
下面为一个 demo:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28PUT /user
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "long"
},
"desc":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"avar_url": {
"type": "text",
"index": false
}
}
}
}
部分属性说明
analyzer:指定字段使用的分词器,默认为standardsearch_analyzer:设置查询时使用的分词器index:指定字段是否索引,默认为true,即要进行索引, 只有进行索引会对对应字段进行倒排索引的建立,之后才可以从索引库搜索到。但是也有一些内容不需要索引,比如说用户图片的地址就不需要进行搜索,此时可以将该值设置为falseignore_above:此参数用于指定一个整数值,表示当一个字符串的长度超过这个值时,这个字符串将被忽略,不会建立倒排索引。注意:ignore_above只能用于keyword类型的字段,不能用于其他类型的字段ignore_above最大值是 32766,需根据场景来设置,比如说中文最大值应该是设定在10922
store:此参数决定了这个字段的原始值是否应该在索引中单独存储。默认情况下,store参数被设置为false,这意味着字段的原始值不会被单独存储,但是仍然可以被搜索和聚合。由于每个文档索引后会在 ES 中保存一份原始文档,存放在source中,一般情况下不需要设置store为true,因为在source中已经有一份原始文档了。以下是一些可能需要将store参数设置为true的情况:- 你需要在搜索结果中返回部分字段:在这种情况下,你可以将这些字段的
store参数设置为true,而不是返回整个_source字段,以节省网络带宽。 _source字段非常大:如果你的文档包含大量的数据,但是你只需要搜索和返回其中的一部分,你可以将这部分数据的store参数设置为true,以节省存储空间和提高搜索效率- 你需要频繁地访问某个字段的原始值:在这种情况下,将这个字段的
store参数设置为true可以提高访问速度
- 你需要在搜索结果中返回部分字段:在这种情况下,你可以将这些字段的
高级——动静结合
对于数据而言,其结构可能是:
- 结构化的:我们可以在创建索引时使用静态映射约束数据字段;
- 非结构化的:我们可以在创建索引时使用默认的动态映射兼容数据字段;
但其实,数据的结构可能既有结构化的又有非结构化的,在此种情况下,无论是使用静态映射还是动态映射,都无法做到对应适配。
对于动态映射而言,官方的解释是为了照顾入门学习者,但实际上我们还是尽可能多的显式声明 mapping,因为显式创建 mapping 是生产环境必须的,这是必须掌握的技能。
因此,为了做到鱼与熊掌兼得,可以手动设置动态映射或使用dynamic_templates(动态模版)。
手动设置动态映射
在动态映射中,存在一些可以手动设置的参数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25PUT /user
{
"mappings": {
"dynamic": true,
"date_detection": false,
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"age": {
"type": "long"
},
"desc": {
"type": "text",
"dynamic": false
},
"avar_url": {
"type": "text",
"index": false
}
}
}
}
dynamic
dynamic:配置动态映射的属性,存在三种状态:
true: :遇到陌生字段,动态添加新的字段(默认值)false:忽略陌生字段,不会建立倒排索引,因此无法被搜索,但会存在于_source中strict:遇到陌生字段,就报错
date_detection——日期探测
如果date_detection被启用(默认),那么新的字符串字段将被检查,看其内容是否与dynamic_date_formats中指定的任何日期模式相匹配。如果发现匹配,一个新的日期字段将以相应的格式被添加。
dynamic_date_formats的默认值是["strict_date_optional_time", "yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"]
比如说发起请求增加一个包含日期型字符串的文档:1
2
3
4PUT my-index-000001/_doc/1
{
"create_date":"2015/09/02"
}
之后查看映射定义:1
GET my-index-000001/_mapping
发现create_date字段已被添加为日期字段,其格式为"yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"
日期探测可以关闭嘛?
当然,我们可以设置date_detection为false来关闭日期自动映射:1
2
3
4
5
6PUT my-index-000001
{
"mappings": {
"date_detection": false
}
}
那么,create_date字段将被添加为一个文本字段。1
2
3
4PUT my-index-000001/_doc/1
{
"create_date": "2015/09/02"
}
日期探测可以自定义吗嘛?
当然,通过dynamic_date_formats定制日期探测,以支持对应业务的日期格式:1
2
3
4
5
6
7
8
9
10
11PUT my-index-000001
{
"mappings": {
"dynamic_date_formats": ["MM/dd/yyyy"]
}
}
PUT my-index-000001/_doc/1
{
"create_date": "09/25/2015"
}
numeric detection——数字探测
虽然 JSON 支持原生的浮点和整数数据类型,但一些应用程序或语言有时会将数字呈现为字符串。通常情况下,正确的解决方案是显式映射这些字段,但numeric detection(数字检测默认情况下是禁用的)可以被启用来自动完成。
举个例子,对某个索引开启数字探测:1
2
3
4
5
6PUT my-index-000001
{
"mappings": {
"numeric_detection": true
}
}
那么,当我们向索引增加字符型的数字字段后:1
2
3
4
5PUT my-index-000001/_doc/1
{
"my_float": "1.0",
"my_integer": "1"
}
将产生一下效果;
my_float字段被添加为一个float类型的字段my_integer字段被添加为一个long类型的字段
dynamic_templates(动态模版)
下面来看个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37{
"mappings": {
"dynamic_templates": [
{
"long_as_integer": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
},
"str_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false,
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
],
"date_detection": true,
"properties": {
"age": {
"type": "long"
},
"avar_url": {
"type": "text",
"index": false
}
}
}
}
在dynamic_templates中,我们配置了以下两条规则:
long_as_integer:设置match_mapping_type属性值为long,在自动识别为long型字段时将其转换为mapping对象type属性定义的integer类型str_as_keywords:设置match_mapping_type属性值为string,在自动识别为string类字段时将其转换为mapping对象type属性定义的text类型及fields属性定义的多字段类型keyword(ignore_above字段值表示最大的字段值长度,超出这个长度的字段将不会被索引,但是会存储,因此部分搜索时将找不到)
注意哦:
fields参数的目的是为了实现multi-fields,即一个字段拥有多种数据类型。比如一个city字段的数据类型为text,用于全文索引,那么通过fields再为该字段定义成keyword类型,可用于排序和聚合(需要通过city.raw使用)
补充说明的参数:
norms:若存储到 ES 的数据在后续搜索时不关注得分,比如从来不按分数对文档进行排序,那么可以禁用索引中这些计分因子,这样可以在存储时节省一些空间。date_detection:默认为true,若识别的字符串格式形如日期,则会将该字段作为作为日期字段添加,如将"create_date": "2015/09/02"添加变为"yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z",因此,一般修改为false来禁用此设置以使类似字段作为文本字段添加
查看映射的信息
我们通过以下命令来查看下前面数据映射中的信息:1
GET /user/_mapping
该命令执行之后,将显示如下信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29{
"user" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
可以看到,年龄值在 ES 中自动转化long类型了,而name和desc字符串则被转化为了keyword类型。
Shard
对 Elasticsearch 索引中的数据而言,其实是被存储在分片(shards)上的。
索引只是一个把一个(或多个)分片汇总在一起的逻辑空间,换而言之,一个索引是一系列分片的集合,分片是数据(文档集合)拆分后的一部分。。
举个栗子:在 ES 中若有 5 个主分片,则每个分片分别存储了一部分的文档集合(如 分片 1 存储了 id 为 1、3、19 的文档集合,分片 2 存储了 id 为 6、22、111 的文档集合,其他分片同理)。
若拿关系型数据库来类比的话,则每个文档对应数据表中的一行,因此分片可类比为数据表的一行或多行。
Replica
除了分片以外,还可以对分片进行备份,备份被称为副本(replica),即每个分片的复制,可以有一个或多个。
相应地,分片有 primary shard(主分片)和备份分片(replica)之分。
主分片和备分片不会出现在同一个节点上(PS:为了防止单点故障),默认情况下一个索引创建 5 个分片和 5 个备份(即 5 primary + 5 replica = 10 个分片)
注意哦:若只有一个节点,5 个副本分片将无法分配,在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。
API 用法
在 Elasticsearch 中,若我们需要对索引进行 CRUD,就需要学习其 API 啦。
由于笔者为 Java 开发,因此将 Elasticsearch 的 API 分为以下 3 类:
- 基础 API:Restful 风格官方基础 API
- Java API(旧):针对 Java 语言的 SDK API 支持
- Java API(新):针对 Java 语言的 SDK API 支持
- Spring Data Elasticsearch API:Spring 针对 Java API 再次封装
以下仅用做回忆之用,具体请参考官方文档。
基础 API
基础 API 遵循 Restful 风格,语法可以分为两部分:
- ① HTTP 请求 + URL 路径
- ② 请求体携带一段 JSON 数据
在 Elasticsearch 中,API 语法遵循 RestFUL 风格。
索引
索引创建
默认
1 | PUT /user |
默认创建的索引主分片和副本分片均为一个:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27GET /user
{
"user" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "user",
"creation_date" : "1670678218564",
"number_of_replicas" : "1",
"uuid" : "RKue26OcTDaCEJR6aaG_OQ",
"version" : {
"created" : "7170699"
}
}
}
}
}
指定分片
如果想创建指定分片的索引可以使用相关参数:1
2
3
4
5
6
7
8
9PUT /user
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
}
上述参数说明如下:
setting:索引相关设置:number_of_shards:设置分片数,默认为 1,每个索引的分片的数量上限为 1024, 这是一个安全限制,以防止意外创建索引, 这些索引可能因资源分配而破坏集群的稳定性。 通过在属于集群的每个节点上指定系统export ES_JAVA_OPTS="-Des.index.max_number_of_shards=128"属性可以修改此限制number_of_replicas:设置备份分片数,默认为 1
索引更新
需要注意的是,索引更新时无法更新主分片数,只能更新副本分片数。
更新副本数量
1 | PUT /user/_settings |
更新分片刷新时间
分片的刷新时间默认情况下为 1s,修改为-1可以禁用刷新。1
2
3
4
5
6PUT /user/_settings
{
"index" : {
"refresh_interval" : "-1"
}
}
更新分页数
from + size搜索索引的最大值默认为 10000,通过以下方式可以修改:1
2
3
4
5
6PUT /user/_settings
{
"index" : {
"max_result_window" : "20000"
}
}
增大分页数的做法是错的,这会降低性能,我们可以通过其他方法来解决此问题。
修改映射
新增创建时间字段:1
2
3
4
5
6
7
8PUT /user/_mapping/_doc
{
"properties": {
"create_time": {
"type": "date"
}
}
}
注意:mapping 只能在创建 index 时建立, 之后修改映射只能在 Mapping 中新增字段 ,而不能修改映射中的已有 field,因为已有数据按照映射早已分词存储好,若修改,无法兼容存量数据。
索引删除
1 | DELETE /user |
为了安全起见,防止恶意删除索引,删除时必须指定索引名,这可以在elasticsearch.yml文件通过以下配置开启:1
action.destructive_requires_name: true
ES索引创建成功之后,以下属性将不可修改:
- 索引名称
- 主分片数量
- 字段类型
索引查询
查询单个索引信息
1 | GET /user |
查看所有索引信息
1 | GET /_cat/indices?v |
返回结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open station_index uZ7VUXZBToCj0GSU2XXIpQ 1 1 3 0 4.6kb 4.6kb
green open .apm-agent-configuration rCxLTU5LQtK40AFMymhZcw 1 0 0 0 283b 283b
yellow open community_user RmM_FWIcSF6X2AdzJF64Mw 5 1 15 0 31.7kb 31.7kb
green open .kibana_1 ZFJrNFtXRpiIC0w6jM7bSA 1 0 112 19 962.9kb 962.9kb
yellow open jd_goods1 rB4e6LGSQvGM3DbAvJ5tKw 1 1 30 0 37.5kb 37.5kb
yellow open cars rd5P8XZnS8usHVe_3HKFrw 1 1 8 0 4.8kb 4.8kb
yellow open logstash-2020.05.20 l-CfDFzpQmmmpWlDQgdpxw 1 1 0 0 283b 283b
yellow open bank yf2CmJTESfKoxQ1RgqmwkA 1 1 1000 0 414.1kb 414.1kb
green open kibana_sample_data_ecommerce Rof8wGgfQD2z0JR_-AKgGQ 1 0 4675 0 4.7mb 4.7mb
green open .kibana_task_manager_1 R2g2v49FSa2d0N-khZhKbw 1 0 2 2 21.7kb 21.7kb
yellow open jd_goods bR4E5_3-Tz-mSp4ygkydKg 1 1 180 0 266.1kb 266.1kb
yellow open shakespeare alhRhphuR8mg8x5wi3QEKQ 1 1 111396 0 19.5mb 19.5mb
yellow open logstash-2020.05.18 h_yqg8tkRv2QPgHqSGQWGA 1 1 0 0 283b 283b
yellow open logstash-2020.05.19 G_5X5Qe6R7md-WGuqFvvYw 1 1 0 0 283b 283b
yellow open user QqLCAewKT2mOcjP4aBgb9g 2 1 0 0 566b 566b
yellow open community_post rXcSTh_tQ1CS5p7vAbeh_g 5 1 9 0 328.9kb 328.9kb
文档
创建文档
下面命令可以创建一个文档:1
2
3
4
5
6POST /user/_doc/1
{
"name": "lovike",
"age": 18,
"desc": "描述信息"
}
如果文档的索引不存在,则会先创建索引在创建文档,这是通过动态映射实现的。
当然,通过以下命令也可以创建文档(索引不存在也先创建索引):1
2
3
4
5
6POST /user/_create/1
{
"name": "lovike",
"age": 18,
"desc": "描述信息"
}
_doc和_create的区别是如果1文档已存在,则_create会执行失败,而_doc能执行成功(更新)。
文档更新
一般通过如下命令进行更新:1
2
3
4
5
6POST /user/_update/1
{
"doc": {
"desc": "描述"
}
}
注意哦:若是通过下面的命令更新,则该数据将仅剩desc类型的了(不推荐使用)1
2
3
4PUT /user/_doc/1
{
"desc": "描述"
}
文档删除
DELETE 请求可以删除文档。
若从索引中删除文档,必须指定索引名和文档 ID,如1
DELETE /user/_doc/1
条件删除
若要删除与指定查询匹配的文档,可以这么做:1
2
3
4
5
6
7
8POST /user/_delete_by_query
{
"query": {
"match": {
"name": "lovike"
}
}
}
还可以从 user 索引中删除所有文档数据:1
2
3
4
5
6POST /user/_delete_by_query?conflicts=proceed
{
"query": {
"match_all": {}
}
}
亦可以同时从多个索引中删除文档:1
2
3
4
5
6POST /user1,user2/_delete_by_query
{
"query": {
"match_all": {}
}
}
总之,结合query的条件,变化多样。
限时删除
执行删除操作时,分配给执行删除操作的主分片可能不可用。
出现这种情况的一些原因可能是主分片目前正在从存储恢复或者正在进行重新定位。
默认情况下,删除操作将在主分片上等待最长 1 分钟,然后失败并用错误作出响应。
Timeout 参数可用于显式指定等待的时间。
下面是一个设置为 5 分钟的例子:1
DELETE /user/_doc/1?timeout=5m
文档查询
基础查询
GET 可以从索引中检索指定的 JSON 文档。1
GET /user/_doc/1
返回结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 14,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "lovike",
"age" : 18,
"desc" : "描述信息"
}
}
关闭源检索
除非已经使用了存储字段参数或者禁用了源字段,默认情况下,GET 操作会返回源字段的内容。
因此,若不关注源字段内容,仅仅想知道查询文档的索引相关信息,可以通过使用 source 参数来关闭源检索:1
GET /user/_doc/1?_source=false
返回结果如下:1
2
3
4
5
6
7
8
9{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 14,
"_primary_term" : 1,
"found" : true
}
只获取源字段
但是,有时我们又仅仅只想看到源字段的信息,那么可以:1
GET /user/_source/1
返回结果如下:1
2
3
4
5{
"name" : "lovike",
"age" : 18,
"desc" : "描述信息"
}
除此之外,我们还可以对源字段进行筛选。
比如只想返回name一列:
1 | GET /user/_search |
批量查询
1 | GET /user/_mget |
1 | { |
滚动查询—— Scroll
虽然 Search API 查询请求会返回对应结果,但是返回被限制了 10000 条,这是 ES 出于安全上面的考量,那么如果确实需要查询出索引中的所有数据,又需要怎么查询呢?
我们知道:不应该去修改某个参数将限制结果条数增大,不仅是由于不知道应该将限制条数增大为多少,而且最重要的是——这样的做法容易造成 OOM。
那么,就没有其他办法了嘛?
自然是有的,ES 的查询中提供了 Scroll API,Scroll API 可以用来从单个搜索请求中检索大量的结果(甚至是所有的结果),其方式与在传统数据库上使用游标的方式基本相同。
需要注意的是:滚动的目的不是为了满足用户的实时请求,而是为了处理大量的数据。例如,为了将一个数据流或索引的内容重新索引到一个具有不同配置的新数据流或索引。
使用指南
如何使用 Scroll API?
首先,Scroll API 需要一个 Scroll ID,而要获得一个 Scroll ID,需要提交一个 Search Scroll API 请求,并指定一个滚动查询参数:1
2
3
4
5
6
7
8
9
10
11
12
13
14POST /operate_log/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": [
{
"createTime": {
"order": "asc"
}
}
],
"size": 10000
}
上面的搜索响应结果会在_scroll_id响应体参数中返回一个滚动 ID。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFks2U2tka3loVEh1enZSOGpqTGlsQncAAAAAAACGChZhUlhxUGFWYlFFQ181aHBKZUFZZEVB",
"took" : 109,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 22534344,
"relation" : "eq"
}
}
}
之后,就可以使用 Scroll API 的滚动 ID _scroll_id来检索该请求的下一批结果:1
2
3
4
5POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFks2U2tka3loVEh1enZSOGpqTGlsQncAAAAAAACF9RZhUlhxUGFWYlFFQ181aHBKZUFZZEVB"
}
注意哦:上面的查询不需要携带之前的任何查询参数(如
match_all),因为其会沿用之前的查询条件。
####### 清除滚动上下文
一个滚动查询会忽略了相关文档的任何后续变化,返回在最初的搜索请求时与搜索条件相匹配的所有文件。
由初始请求创建的scroll_id将标识一个搜索上下文,其记录了 ES 为返回正确的文档所需要的一切,并在后续请求保持活跃状态。scroll参数(传递给搜索请求和后续每个滚动请求)代表保持搜索上下文的时间(例如:1m,见时间单位)。scroll参数的值不需要长到足以处理所有的数据,它只需要长到足以处理前一批次查询结果(比如给定的最大限制是 10000)。
每个滚动请求都应通过scroll参数设置一个到期时间。
如果一个滚动请求没有传入scroll参数,那么搜索上下文将作为该滚动请求的一部分被释放,这代表着本次scroll请求结果将不再返回scroll_id。
下面为设置了滚动参数和未设置滚动参数的scroll请求:1
2
3
4
5POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFks2U2tka3loVEh1enZSOGpqTGlsQncAAAAAAACF9RZhUlhxUGFWYlFFQ181aHBKZUFZZEVB"
}
1 | POST /_search/scroll |
Scroll 超过设置的超时时间后,搜索上下文会自动删除。虽然如此,但保持 Scroll 打开是有代价的,因此一旦用完 Scroll API ,就应明确清除 Scroll 的上下文。
下面是清除单个上下文和多个上下文的请求:1
2
3
4DELETE /_search/scroll
{
"scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFks2U2tka3loVEh1enZSOGpqTGlsQncAAAAAAACFjxZhUlhxUGFWYlFFQ181aHBKZUFZZEVB"
}
1 | DELETE /_search/scroll |
安全限制
若 ES 的安全功能被启用,对特定 Scroll ID 的结果的访问被限制在提交搜索的用户或 API 密钥上。
分页推荐使用 search_after
高版本 ES 不再推荐使用 Scroll API 进行深度分页,因为其无法保存索引状态。
。若需要在分页超过 10000 次时保留索引状态,可使用带有时间点(PIT)的search_after参数,性能更优哦!
高级查询—— DSL
由于 DSL 高级查询相关概念非常多,因此单独通过一篇文章分析,本文只做简单介绍。
数据纵览——聚合
聚合亦单独抽离一篇文章来分析,本文只做简单介绍。
文档批量操作
Bulk 是 ElasticSearch 提供的适用于批量操作的 API,可以实现数据批量的添加、修改、删除。
Bulk 减少了 IO 次数,可以提高效率,因此使用较多。
Bulk 会把将要处理的数据载入内存中,因此数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于硬件,文档大小,复杂性,索引、以及搜索的负载。一般建议是 1000-5000 个文档,大小建议是 5-15M,默认不能超过 100M,可以在配置文件elasticsearch.yml中配置。
Bulk 格式包含请求行为action和请求数据requestbody,这两个是一条命令,但是要换行,如下:1
2
3
4
5POST /indexName/_bulk
{
{action:{metatata}}
{requestbody}
}
action操作行为包含以下几种:
create:文档不存在时创建update:更新文档index:创建新文档或替换已有文档delete:删除一个文档
create和index的区别在于:若数据存在,使用create会提示文档已经存在,操作会失败,而使用index则可以成功执行。
metatata中包含_index,_type,_id及要执行的索引、类型、文档 id(当然也可以不填)。
下面为一个简单栗子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17POST /cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2020-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2020-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2020-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2020-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2020-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2020-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2020-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2020-02-12" }
Java API(新)
ES 的 Java API 使用语法一直为人所诟病,因此 ES 在 7.15 版本后新增了一种语法更简洁的 Java API Client。
Java API Client 具有以下特性:
- 所有 API 提供强类型的请求和响应
- 所有 API 均提供阻塞和异步两种版本
- 使用流畅的构建器和功能模式,以便在创建复杂的嵌套结构时编写简明而可读的代码
- 通过使用对象映射器(如 Jackson 或任何 JSON-B 的实现),可实现应用程序类的无缝集成
- 将协议处理委托给一个 HTTP 客户端,如 Java Low Level REST Client ,其负责所有传输级的问题:HTTP 连接池、重试、节点发现,等等
快速入门
首先,我们需要在 Maven 项目引入以下依赖:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>7.17.8</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.0.1</version>
</dependency>
其次,我们就需要考虑如何使用 ES 的 Java API Client 了。
Java API Client 的结构是围绕着三个主要组件。
- API Client 相关类:这些类为 ES API 提供了强类型的数据结构和方法。由于 ES 的 API 很大,它的结构是以功能组(也称为 “命名空间”)为单位,每个功能组都有自己的客户端类。ES 的核心功能就是在 ElasticsearchClient 类中实现的。
- 一个 JSON 对象映射器,可将你的应用程序类映射为 JSON,并将它们与 API 客户端无缝集成
- 一个传输层的实现。这是所有 HTTP 请求处理发生的地方
下面的代码创建并连接了这三个组件:1
2
3
4
5
6
7
8
9
10// Create the low-level client
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
ElasticsearchClient client = new ElasticsearchClient(transport);
注:认证是由 Java Low Level REST Client 管理的,若需要认证配置,请参考其文档查看进一步细节。
最后,就是具体的使用了。
下面的代码片段从products索引中搜索名称与bicycle匹配的所有项目,并将它们作为产品应用类的实例返回:1
2
3
4
5
6
7
8
9
10
11
12SearchResponse<Product> search = client.search(s -> s
.index("products")
.query(q -> q
.term(t -> t
.field("name")
.value(v -> v.stringValue("bicycle"))
)),
Product.class);
for (Hit<Product> hit: search.hits().hits()) {
processProduct(hit.source());
}
上述代码描述了如何使用流畅的函数式构建器,将搜索查询写成简洁的 DSL 式代码。这种模式在后面有更详细的说明。
探秘 Java API Client
Java API Client 使用非常一致的代码结构,通过更符合潮流趋势的代码模式,使复杂的请求更容易编写,复杂的响应更容易处理。
下面的章节将详细介绍。
包结构和命名空间客户端
在 Elasticsearch API 文档中可以获悉:Elasticsearch API 库非常大,其被合理地组织成不同的功能组。
Java API Client 同样遵循功能组结构:
- 功能组被称为
namespaces(命名空间) - 每个命名空间位于
co.elastic.client.elasticsearch的一个子包中 - 每个命名空间的客户端都可以从顶层的Elasticsearch客户端访问。唯一的例外是
Search API和Document API,它们位于核心子包中,可以在主 Elasticsearch 客户端对象上访问
下面的片段展示了如何使用索引命名空间客户端来创建一个索引(lambda语法在构建API对象中解释)。1
2
3
4// 创建 "products" 索引
ElasticsearchClient client = ...
client.indices()
.create(c -> c.index("products"));
方法命名惯例
Java API Client 中的类包含两种方法和属性:
- 方法和属性是API的一部分,例如
ElasticsearchClient.search()或SearchResponse.maxScore(),它们是从 Elasticsearch JSON API 中各自名称中衍生而来,使用了标准的 Java 驼峰命名规则 - 方法和属性是构建 Java API Client 的框架的一部分,例如
Query._kind()。这些方法和属性的前缀是下划线,以避免与 API 名称发生任何命名冲突,同时也是区分 API 和框架的一种简便方法
阻塞和异步客户端
Java API Client 有两种类型:阻塞型和异步型,异步客户端的所有方法都返回一个标准的 CompletableFuture。
根据需要,两种口味都可以同时使用,共享同一个传输对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22ElasticsearchTransport transport = ...
// 同步阻塞客户端
ElasticsearchClient client = new ElasticsearchClient(transport);
if (client.exists(b -> b.index("products").id("foo")).value()) {
logger.info("product exists");
}
// 异步非阻塞客户端
ElasticsearchAsyncClient asyncClient =
new ElasticsearchAsyncClient(transport);
asyncClient
.exists(b -> b.index("products").id("foo"))
.whenComplete((response, exception) -> {
if (exception != null) {
logger.error("Failed to index", exception);
} else {
logger.info("Product exists");
}
});
构建 API 对象
列表和地图
变体类型
对象的生命周期和线程安全
由 JSON 数据创建 API 对象
异常情况
Java API Client 会抛出两种类型的异常:
- 若发送到 ES 服务器的请求被拒绝,比如说验证错误、服务器内部超时等,将产生一个
ElasticsearchException,这个异常包含了由 ES 提供的关于错误的详细信息 - 若请求未能到达服务器,比如网络错误、服务器不可用,等等,将产生一个
TransportException。由于该异常的原因是下层实现类所抛出的异常,因此在RestClientTransport的情况下,它将是一个ResponseException,其包含低级别的 HTTP 响应结果
用法说明
下面将介绍 Java API Client 最常用的和一些不太明显的功能的教程。
如需完整的参考资料,请参见 Elasticsearch文 档,特别是 REST APIs 部分。Java API Client 使用其规则语法严格遵循那里描述的 JSON 结构。
为单个文件编制索引
Java API Client 提供了几种索引数据的方法:
- 你可以提供将自动映射到JSON的应用对象
- 或者你可以提供原始JSON数据。
使用应用对象更适合于具有明确领域模型的应用,而原始JSON更适合于具有半结构化数据的日志用例。
构建请求的最直接方式是使用流畅的DSL。在下面的例子中,我们在产品索引中索引了一个产品描述,使用产品的SKU作为索引中的文档标识。产品对象将通过Elasticsearch客户端上配置的对象映射器被映射为JSON。
批量:为多个文件编制索引
批量请求允许在一个请求中向 ES 发送多个文档相关的操作。当有多个文档需要存储时,批量请求比用单独的请求发送每个文档效率更高。
一个批量请求可以包含几种操作。
- 创建一个文档,在确保该文档不存在的情况下为其建立索引
- 为一个文档建立索引,如果需要,则创建该文档,如果存在,则替换该文档
- 更新一个已经存在的文档,可以用一个脚本或部分文档
- 删除一个文档
一个BulkRequest包含一个操作的集合,每个操作都是一个有几个变体的类型。要创建这个请求,方便的做法是为主请求使用一个构建器对象,为每个操作使用流畅的DSL。
下面的例子显示了如何为一个列表或应用程序对象建立索引
按ID读取文档
搜索文档
聚合
高级功能
检索
类似于 MySQL 的查询(过滤,分页,排序),Elasticsearch 提供了基于 JSON 的完整的查询 DSL(领域特定语言)来定义查询。
详细介绍见本系列第二篇文章。
聚合
什么是聚合?
在聚合之前,ES 致力于搜索,若想通过一个查询得到匹配该查询的文档集,搜索如同在大海捞针。
但通过聚合,我们将得到一个数据的概览。
因此,若我们需要的是纵览和分析全部的数据而不是寻找单个文档,比如说想要知道:
- 世界上有多少手机厂商?
- 每月新增的手机厂商有多少?
- 按照手机厂商来划分,手机的平均定价是多少?
通过聚合,可以搜寻到以上问题的答案,并且聚合也可以回答更加细微的问题,比如说:
- 最受欢迎的手机厂商是哪家?
- 目前性能最高的手机是哪家厂商的?是哪一款?
聚合允许我们向数据提出一些复杂的问题。虽然功能完全不同于搜索,但它使用相同的数据结构。
这意味着聚合的执行速度很快并且就像搜索一样几乎是实时的。
对报告和仪表盘来说,聚合功能是非常强大的。
比如说,实时显示的数据可以让你立即处理,而不是对数据进行汇总( 需要一周时间去运行 Hadoop 任务 ),报告还可以随着你的数据变化而变化,而不是预先计算的、过时的和不相关的。
最后,聚合和搜索是同级别的。
这意味着你可以在单个请求里同时对相同的数据进行搜索/过滤和分析,并且由于聚合是在用户搜索的上下文里计算的,不只是显示相关数据的数量,而是显示匹配查询条件的相关数据的数量。
详细介绍见本系列第三篇文章。
集群
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。
通过集群,可使 ElasticSearch :
- 备份数据——应对故障,快速恢复
- 提升性能——更快的存储与相应
详细介绍见本系列第四篇文章。
下载与安装
ElasticSearch
从 Elasticsearch 的官网下载压缩包,解压后的目录结构如下:1
2
3
4
5
6
7
8
9
10├── bin # 启动相关
├── config # 配置
├── data # 数据(需手动创建)
├── lib # 相关 jar 包
├── logs # 日志
├── modules # 功能模块
├── plugins # 插件
├── LICENSE.txt
├── NOTICE.txt
└── README.textile
注:若是低版本 的Elasticsearch,其运行依赖于 JDK,所以需要先安装 JDK。
配置修改
启动 Elasticsearch 前,一般需要对config目录下的配置文件elasticsearch.yml,进行一些参数的修改:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:设置集群名称
#
#cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:设置当前节点名称
#
#node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):数据存放位置
#
#path.data: /path/to/data
/usr/local/Cellar/elasticsearch-7.6.1/data
#
# Path to log files:日志存放位置
#
#path.logs: /path/to/logs
/usr/local/Cellar/elasticsearch-7.6.1/logs
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):设置 IP 地址
#
#network.host: 192.168.0.1
# 允许任何 ip 访问
network.host: 0.0.0.0
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.seed_hosts: ["host1", "host2"]
discovery.seed_hosts: ["127.0.0.1"]
注意点
注:若主机性能不够时可以修改config下的jvm.options相关参数:
1 | # 修改前 |
Docker 安装
1 | cat >>docker-compose.yml <<EOF |
Kibana
什么是 Kibana?
Kibana 是一个基于 Node.js 的 Elasticsearch 索引库数据统计工具,它可以利用 Elasticsearch 的聚合功能,生成各种图表,如柱形图,线状图,饼图等等。
Kibana 还提供了操作 Elasticsearch 索引数据的控制台,并且提供了 ES API 的相关提示,非常有利于 Elasticsearch 的语法学习。
安装与启动
从Kibana 的官网下载压缩包,解压完成后,进入bin目录通过kibana启动,之后便可通过5601端口访问 Kibana 界面。
注意哦:Kibana 依赖 Node.js,且其下载版本必须和 Elasticsearch 保持一致。
国际化
默认情况下,Kibana 界面语言以英文显示,不过我们可以修改为中文,只要将 Kibana 下载后的config目录下的kibana.yml文件修改一下即可。
具体修改如下:1
2#i18n.locale: "en"
i18n.locale: "zh-CN"
IK 分词器
IK 分词器可以说是对中文分词最友好了。
下载安装
下载需要去官网选择对应版本。
下载并解压完成后,首先在 Elasticsearch 的plugins目录下创建ik-analyzer文件夹,之后将解压完的所有文件放入即可。
注意哦:IK 分词器版本必须与 Elasticsearch 保持一致
配置文件
在 ik 的config目录下存放了以下配置文件:1
2
3
4
5
6
7
8
9
10
11
12
13.
├── IKAnalyzer.cfg.xml # 用于配置自定义词库
├── extra_main.dic # 扩展中文词库,大概 40 万条单词
├── extra_single_word.dic #
├── extra_single_word_full.dic #
├── extra_single_word_low_freq.dic #
├── extra_stopword.dic # 扩展停用词
├── main.dic # ik 原生内置的中文词库,总共有 27 万多条
├── preposition.dic #
├── quantifier.dic # 放了一些单位相关的词
├── stopword.dic # 英文停用词
├── suffix.dic # 一些后缀词,如乡、井、亭等
└── surname.dic # 百家姓
自定义扩展
对于一些特殊的流行词,如鬼畜,一般不会在 ik 的原生词典里, 需要自定义补充。
若需要扩展停止词(停止词指无太大意义的词,如的、了、吧),亦可自定义补充。
因此,可以将IKAnalyzer.cfg.xml 修改如下:1
2
3
4
5
6
7
8
9
10
11
12
13
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/custom_dict.dic;custom/custom_single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/custom_ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
之后创建custom文件夹及相关扩展字典。
分词方式
对 IK 分词器而言,分词方式又有 2 种:
ik_max_word:最细粒度拆分ik_smart:最粗粒度拆分
什么是最细粒度拆分,什么又是最粗粒度拆分呢?
请看下面两个例子。
ik_max_word——最细粒度拆分
对“中华人民共和国人民大会堂”使用ik_max_word进行分词:1
2
3
4
5GET /_analyze
{
"text": ["中华人民共和国人民大会堂"],
"analyzer": "ik_max_word"
}
下面为拆分后的结果:
1 | { |
可以看到,对于最细粒度拆分而言,拆分的结果词语非常多。
ik_smart——最粗粒度拆分
那么最粗粒度拆分又会怎么拆分呢?1
2
3
4
5GET /_analyze
{
"text": ["中华人民共和国人民大会堂"],
"analyzer": "ik_smart"
}
下面来看下结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "人民大会堂",
"start_offset" : 7,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 1
}
]
}
可以看到,对于最粗粒度拆分而言,只会拆分出 2 个词。
参考
- Elasticsearch 官网
- Elasticsearch 权威指南
- Elasticsearch 7.6 官方文档
- Elasticsearch 7.6 Java REST Client 客户端
- Elasticsearch 7.17 Java API Client
文章信息
| 时间 | 说明 |
|---|---|
| 2020-08-12 | 增加序言部分 |
| 2021-01-02 | 内容重新排版 |
| 2021-06-27 | 独立集群一文 |
| 2022-02-03 | 重大重构 |
| 2022-12-01 | 增加 Java API Client 一节 |