简介
哈希表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做哈希函数,存放记录的数组称做哈希表。
一个通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名 x 到首字母 F(x) 的一个函数关系),在首字母为 W 的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中哈希函数的函数法则 F(x) ,存放首字母的表对应哈希表。关键字和函数法则理论上可以任意确定。
特点
- 高效的查找插入:哈希表通过使用哈希函数将键映射到存储桶中,从而实现快速的查找和插入操作。在理想情况下,哈希表的查找和插入操作可以在常数时间内完成
- 快速的删除操作:哈希表支持快速的删除操作,通过查找键的哈希值,定位到对应的存储桶,并删除特定的键值对
- 均匀的数据分布:哈希函数应该尽可能地将不同的键值映射到不同的存储桶中,以实现均匀的数据分布。这样可以避免存储桶中的元素过多,提高了查找和插入的效率
- 灵活的存储空间:哈希表的大小可以根据需要进行动态调整。当哈希表中的元素数量增加时,可以通过扩展存储桶数量或增加桶的容量来保持性能,并避免过多的哈希冲突
- 冲突需要处理:由于不同的键值可能映射到相同的存储桶中,可能会出现哈希冲突。常见的冲突处理方法包括链地址法(Chaining)和开放地址法(Open Addressing)。链地址法将冲突的元素存储在同一个存储桶中的链表或其他数据结构中。开放地址法尝试在其他存储桶中查找空槽来解决冲突
- 适用于大规模数据:哈希表在处理大规模数据时表现出色。由于其平均时间复杂度为常数级别,即使在大规模数据集上,仍能保持较高的性能
设计思路
哈希表从设计上而言,只需要关注三个问题:
- 如何理解哈希函数?
- 如何定义哈希函数?
- 如何解决哈希冲突?
基本概念
哈希函数
哈希表的核心在于如何理解哈希函数。
从定义上来讲,哈希函数是一个将”键“转换为“哈希值”的函数,即无论你给它什么数据,它都还你一个数字。
其中,哈希函数的”键“可以代表任何数据,比如:
- 某个日期
- 一个字母
- 一串字符
- 学生学号
- 人的姓名
- 人的身份证号
我们可以人为的将学生的姓名作为“键”,手动指定固定其“哈希值”,比如下面是某个班级学生姓名的哈希表,我们人为的将学生姓名(“键”)映射到了学号(“哈希值”)上:
| 学号(哈希值) | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 学生姓名 | 张三 | 李四 | 王五 | 赵六 | 钱七 |
当然,更多情况下,哈希函数还是存在规律,而不是像上面那样没有规律人为控制。
比如在某个算法题中的使用哈希表:
1 | 给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。 |
上题中数组array其实就是一个哈希表,因为数组可以通过索引找到相关的元素,而我们将字符与索引建立了一种函数关系(a --> 0、b --> 1),将不同字符出现的频率存储在数组不同的索引中,从而实现了题目中的需求。
哈希函数的设计
从上面一个小节可知:哈希函数的设计是哈希表最重要的一环。
那么,“键“应当转换为什么类型的“哈希值“比较合适呢?
无论是什么类型的键(整型、浮点型、字符串等等),都可以基于哈希函数转成整型处理,只不过在转换时我们需要注意一些额外的考量。
整型
对于整型的数据,又分为:
- 小范围正整数——可以直接当做哈希值使用
- 小范围负整数——可以进行偏移(比如将
-100~100偏移为0~200),有符合的数据类型也可以不进行偏移,之后当做索引使用 - 大整数(重点介绍)
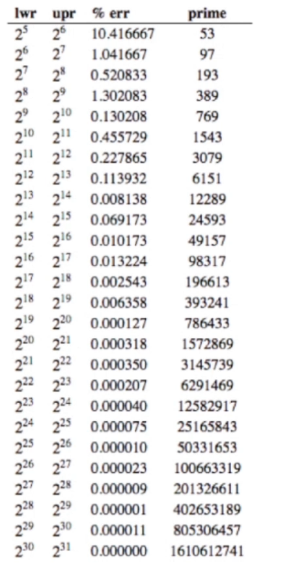
对于大整数,如身份证号,此时就不适合直接当做索引了,一般做法是取模。但取模该怎么去?取后四位?还是后六位?这种取模的做法都没有利用到所有的信息,容易出现哈希冲突。最好的做法是模一个素数,因为这样得到的索引不容易重复,从下表可以很容易的得出该结论:
| 模 4 | 模 7 |
|---|---|
| 10 % 4 = 2 | 10 % 7 = 3 |
| 20 % 4 = 0 | 20 % 7 = 6 |
| 30 % 4 = 2 | 30 % 7 = 2 |
| 40 % 4 = 0 | 40 % 7 = 4 |
| 50 % 4 = 2 | 50 % 7 = 1 |
那对不同的整数进行取模,取模时的素数取何值比较合适呢?
这自然有相关数学研究,对不同规模的数据取模的素数参照下图:
浮点型
浮点型数据在计算机中都是 32 位或 64 位的二进制表示,只不过计算机解析成了浮点数(符号位,阶码,尾数),直接转成整型处理就好。
字符串
字符串我们也可以转成整型处理:
1 | 166 = 1 * 10^2 + 6 * 10^1 + 6 * 10^0 |
复合类型
复合类型我们也可以转成整型处理:
1 | hash(code) = ((((c % M) * B + o) % M * B + d) % M * B + e) % M |
哈希表的扩容:再哈希
对于使用平方探测的开放定址哈希法,如果哈希表填得太满,那么操作的运行时间将开始消耗过长,且插入操作可能失败。这可能发生在有太多的移动和插人混合的场合。此时,一种解决方法是建立另外一个大约两倍大的表(而且使用一个相关的新哈希函数),扫描整个原始哈希表,计算每个(未删除的)元素的新哈希值并将其插人到新表中。
哈希冲突的解决方案
在哈希表中,如果当一个元素被插人时与一个已经插人的元素哈希到相同的值,那么就产生一个冲突,这个冲突应当消除。
如何解决哈希冲突呢?
解决哈希冲突的方法多种多样,我们将讨论其中最简单的两种:
- 链地址法:将冲突的元素存储在同一个存储桶中的链表或其他数据结构中
- 开放定址法:尝试在其他存储桶中查找空槽来解决冲突
疑问:哈希表中一定存在哈希冲突嘛?
如果直接使用数组作为哈希表,人为固定死哈希函数,那么自然没有哈希冲突,因此这个问题的答案是不一定。
小结
通过本文,我们首先了解了哈希表的一些基本概念及特点,其次,我们理解哈希函数到底是什么,最后,我们知道了哈希冲突的两种解决方案。
文章信息
| 时间 | 说明 |
|---|---|
| 2018-12-18 | 初稿 |