简介
堆栈(英语:stack)又称为栈或堆叠,是计算机科学中一种特殊的串列形式的抽象数据类型,其特殊之处在于只能允许在链表或数组的一端(称为堆栈顶端指针,英语:top)进行加入数据(英语:push)和输出数据(英语:pop)的运算。另外堆栈也可以用一维数组或链表的形式来完成。堆栈的另外一个相对的操作方式称为队列。
特点
- 栈是一种线性结构
- 相比数组,栈允许的操作为数组的操作子集
- 只能从一端添加元素,也只能从一端取出元素
- 按后进先出(LIFO, Last In First Out)原理运作
操作
对栈这个数据结构而言,会使用到三种基本操作:
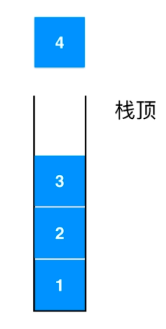
- 压栈(push):将数据放入栈的顶端,栈顶端 top 指针加一
- 出栈(pop):将顶端数据数据弹出,栈顶端数据减一
- 查询(peek):查看顶端存放的数据
图示
设计思路
栈从设计上只要遵循后进先出原则即可,因此在实现栈时,需要限制在栈中操作数据时,只能从顶端添加元素,也只能顶端取出元素。
另外,在栈的底层数据结构的选型中,可以使用数组,也可以使用链表。但与数组相比,个人更喜欢链表,因为:
- 动态扩容:链表天然可以根据需要动态增长或缩小,数组需要额外处理
- 空间效率:链表可以动态分配内存,只使用实际需要的空间。相比之下,使用数组作为底层实现可能需要预留一定的额外空间,以便在需要时进行扩容,数组存在空间浪费情况
- 实现简单性:链表的实现相对较为简单,通常只需要管理节点之间的指针关系。相比之下,数组可能需要处理内存的分配、拷贝和扩容等复杂操作
哦,对了,无论基于哪种方式去实现栈,都应该遵循以下接口定义的规范:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36public interface Stack<E> {
/**
* 元素个数
*
* @return
*/
int size();
/**
* 判空
*
* @return
*/
boolean isEmpty();
/**
* 元素入栈
*
* @param e
*/
void push(E e);
/**
* 栈顶元素出栈
*
* @return
*/
E pop();
/**
* 查看栈顶元素
*
* @return
*/
E peek();
}
数组栈
由于栈的功能属于数组的子集,因此可以直接调用数组的方法来实现栈的代码,只要做一些简单的处理即可。
代码实现
1 | public class ArrayStack<E> implements Stack<E> { |
为了使该栈能动态扩容,加入以下优化:
1 | // 将旧栈指向一个新栈(新栈长度可以自定义) |
push 代码优化:
1 | // 指定元素压栈 |
pop 代码优化:
1 | // 栈顶元素出栈 |
测试
1 |
|
结果
1 | Stack size = 1 ,capacity = 10 :[0] |
链表栈
借助链表实现栈非常简单,只不过需要注意下选择链表头还是链表尾作为栈顶。
为什么这么说呢?
对于单链表来说,向头部进行所有操作的时间复杂度相同,都是 O(1) 级别的,但是向链尾进行的操作就是 O(N) 级别,所以一般都是以链表头作为栈顶。
代码实现
1 | public class LinkedListStack<E> implements Stack<E>{ |
测试
1 |
|
结果
1 | LinkedListStack top:linkedlist:0-->NULL |
时间复杂度
由于栈的结构比较简单,时间复杂度主要依靠底层是如何实现的,数组和链表的操作时间复杂度基本一致:
| 操作 | 时间复杂度 |
|---|---|
| void push(E) | O(1) 均摊 |
| E pop() | O(1) 均摊 |
| E peek() | O(1) |
| int getSize() | O(1) |
| boolean | O(1) |
业务场景
栈在许多业务场景中都会使用,比如:
- 撤销/恢复操作:在许多应用程序中,用户可以执行一系列操作,例如撤销文本编辑操作、浏览器的后退操作等。栈可以用于跟踪操作历史记录,每当用户执行一个操作时,将该操作推入栈中,需要撤销时则从栈顶弹出最近的操作
- 函数调用/递归:在编程中,函数调用和递归的实现往往依赖于栈。当一个函数被调用时,其相关的信息(如参数、返回地址等)被推入栈中,函数执行完毕后,这些信息从栈顶弹出,程序恢复到调用点继续执行
- 表达式求值:在计算机科学中,栈常被用于表达式求值,特别是中缀表达式转换为后缀表达式,并计算后缀表达式的值时。运算符可以按照优先级顺序入栈,操作数则进行计算
- 浏览器历史记录:Web 浏览器通过使用栈来跟踪用户的浏览历史记录。每次访问一个新的页面,该页面的 URL 被推入栈中,当用户点击”后退”按钮时,最近访问的页面 URL 从栈顶弹出
- 括号匹配:栈可以用于检查表达式中的括号是否匹配。当遇到左括号时,将其推入栈中,当遇到右括号时,检查栈顶元素是否为相应的左括号,若匹配则弹出栈顶元素,继续处理表达式
- 深度优先搜索(DFS)和回溯算法:在图的深度优先搜索和回溯算法中,栈被用于存储待访问的节点。通过将当前节点的邻居节点推入栈中,可以实现深度优先的遍历。在迷宫求解算法中,可以使用栈来实现深度优先搜索(DFS)。通过将探索路径推入栈中,可以回溯到之前的决策点,并继续探索其他路径
小结
通过本文,我们首先了解了栈的一些基本概念,其次,在我们需要自定义实现栈时,思考了一些需要注意的问题,最后,我们通过对栈底层选型数组和链表分别进行了一个具体的代码实现,并分析了不同方法执行时的时间复杂度情况,以及栈在具体哪些业务场景中会使用到。
文章信息
| 时间 | 说明 |
|---|---|
| 2018-12-02 | 初稿 |
| 2023-08-19 | 部分重构 |